На днях диагностировал утечку памяти в кластере haproxy, в процессе исследования допустил несколько ошибок, что привело к более долгой локализации проблемы.
На примере данного кейса хочу провести небольшое ретро.
Моя основная деятельность связана с поиском и устранением проблем, негативно влияющих на производительность системы в целом, будь то runtime приложения, сеть, слой виртуализации, база данных или что-угодно еще.
В этот раз по OOM прибило несколько экземпляров haproxy - согласитесь событие нестандартное. Требовалось понять причины и предложить решение.
Сбор контекста
node_exporter показывает планомерный рост потребления памяти (RAM Used), с локальными и скорее всего несущественными скачками:
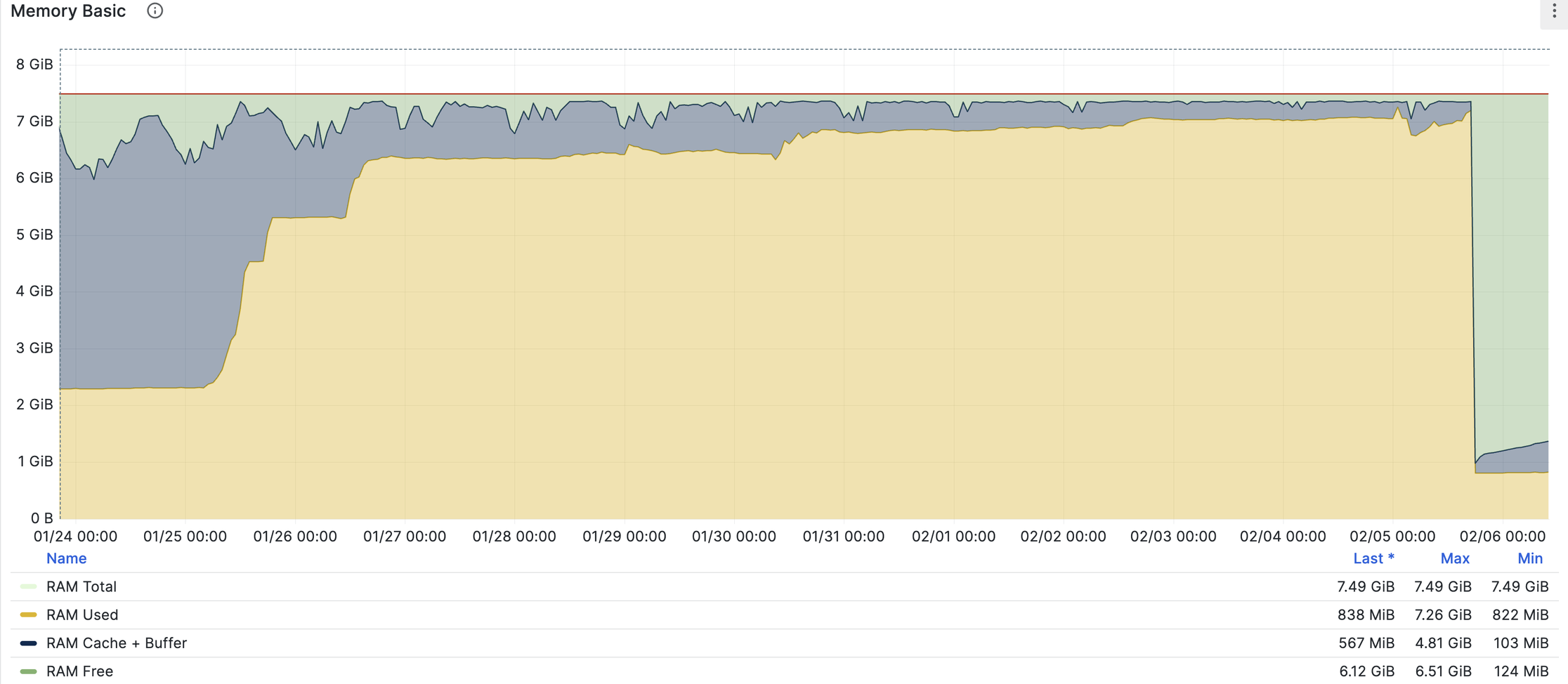
Лог OOM события указывает, что утекли именно процессы haproxy (вывод порезан):
$ dmesg -T | grep oom
...
Tasks state (memory values in pages):
[ pid ] rss name
...
[2887591] 1124 haproxy
[2887593] 83058 haproxy
[2931744] 226614 haproxy
[3093691] 37094 haproxy
[3165698] 33991 haproxy
[3180514] 52974 haproxy
[3192011] 127215 haproxy
[3246961] 150239 haproxy
[3280907] 209137 haproxy
[3310000] 199742 haproxy
[3387199] 21094 haproxy
[3387315] 77567 haproxy
[3408004] 226766 haproxy
[3776117] 230883 haproxy
[ 170279] 142573 haproxy
[ 218073] 265815 haproxy
[ 402741] 183463 haproxy
[ 509821] 76463 haproxy
[ 515738] 194395 haproxy
[ 586958] 27402 haproxy
[ 599282] 100527 haproxy
[ 636940] 231200 haproxy
[ 912356] 170641 haproxy
[1270565] 168217 haproxy
[1664780] 54852 haproxy
[1677084] 27638 haproxy
[1751081] 228705 haproxy
...
Out of memory: Killed process 218073 (haproxy) total-vm:1347736kB, anon-rss:1058308kB, file-rss:108kB, shmem-rss:4844kB, UID:110 pgtables:2244kB oom_score_adj:
...
значения
rssколонки считаются в страницах виртуальной памяти, в данном случае каждая страница равна 4096 байт.
В логах haproxy и его systemd юнита не было ничего необычного, только рестарты от коллег команды управления трафиком.
Я стал погружаться в графики далее и увидел занятную лесенку в объеме памяти под TCP сокеты:
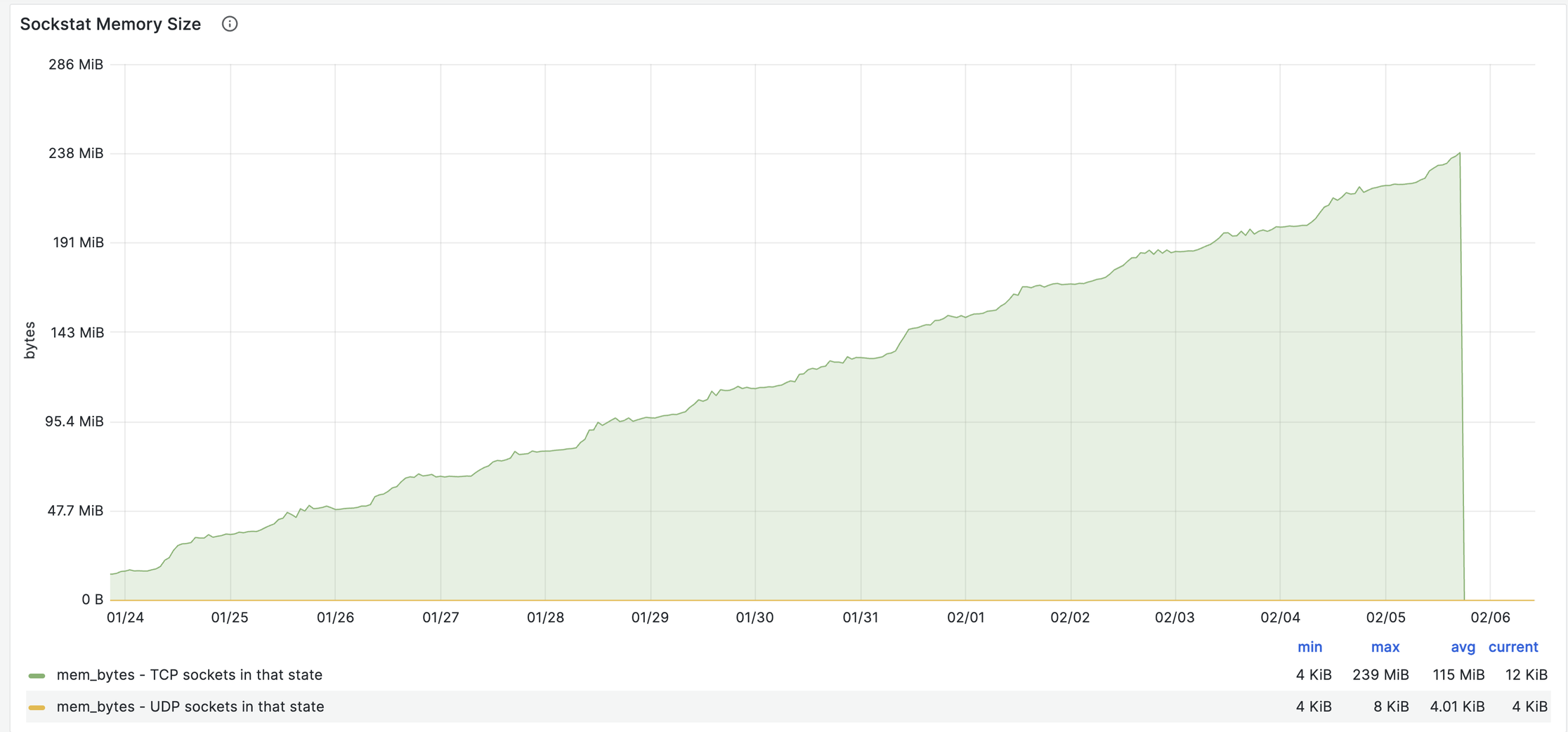
это общесистемная метрика и в данном случае ей можно доверять, так как haproxy живет в хостовом network namespace.
Локально на машине было обнаружено множество established TCP-коннектов с данными на чтение в приемных буферах:
$ ss -nta state established -mO | awk '{ if ( $1 > 0 ) print }'
Recv-Q Send-Q Local Address:Port Peer Address:Port Process
299846 0 10.10.24.5:59390 10.10.8.124:80 skmem:(r407424,rb425984,t0,tb425984,f2176,w0,o0,bl0,d12)
293893 0 10.10.24.5:60060 10.10.8.123:80 skmem:(r399552,rb425984,t0,tb425984,f1856,w0,o0,bl0,d10)
296359 0 10.10.24.5:49260 10.10.8.125:80 skmem:(r406144,rb425984,t0,tb425984,f3456,w0,o0,bl0,d15)
303378 0 10.10.24.5:33750 10.10.8.123:80 skmem:(r417024,rb425984,t0,tb425984,f768,w0,o0,bl0,d10)
299837 0 10.10.24.5:59202 10.10.8.125:80 skmem:(r413568,rb425984,t0,tb425984,f128,w0,o0,bl0,d12)
303536 0 10.10.24.5:37230 10.10.8.124:80 skmem:(r417536,rb425984,t0,tb425984,f256,w0,o0,bl0,d13)
303492 0 10.10.24.5:45944 10.10.8.125:80 skmem:(r415360,rb425984,t0,tb425984,f2432,w0,o0,bl0,d16)
...
Recv-Q- сколько байт данных ожидает чтения, аskmem_r- сколько всего выделено памяти под сокет (Recv-Q+metadata), подробнее про это тут.
Интересно, что подобные коннекты существовали только на балансировщике, в апстримах их не было.
Флаг -i даст чуть больше информации о соединении (вывод сокращен):
$ ss -nta state established -Oi | grep -A 1 59390
299846 0 10.10.24.5:59390 10.10.8.124:80 ...cubic...lastsnd:369593792 lastrcv:369592940 lastack:369592940
Поля last* говорят, что соединение стагнирует на протяжении 369592940 ms, что равно более 100 часам.
Значения last* каждого “зависшего” соединения различалось, но в целом они группировались по интервалам. Я отметил это, но в целом прошел дальше (а зря!).
В тоже время среднее количество TCP сокетов продолжало синхронно расти:
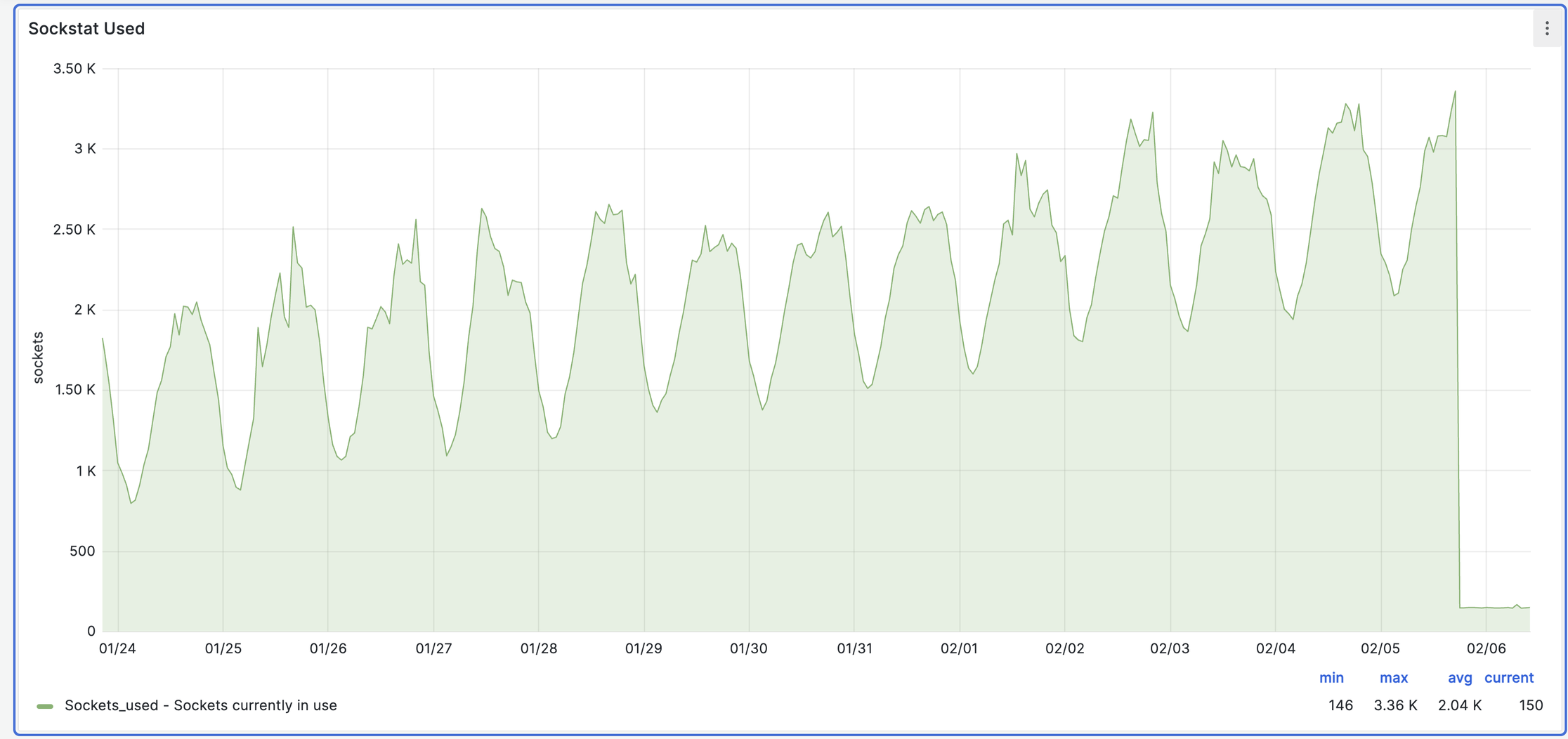
Кажется я напал на след!
haproxy по какой-то причине накапливает коннекты полные данных и не хочет (не может?) вычитать их. Я сформировал гипотезу - память расходуется за счет “повисших” коннектов.
💡 Да-да, тут скорее натягивание совы на глобус, так как под коннекты в пике было выделено ~240MB, что конечно не увязывается с общими потерями. Но что если haproxy под эти коннекты удерживает толстые объекты в памяти?
В общем корреляция очевидна и я начал раскручивать эту версию.
Проверка гипотез
TCP keepalive механизмы могли бы помочь в закрытии старых коннектов, но они включаются только при отсутствии данных в буферах (проверял поведение через снятие дампа трафика и движений пакетов в сокете замечено не было).
Но почему эти данные никто не читает? Процессы (владельцы сокетов) выглядят вполне живыми.
После беглого анализа я не смог дать объяснение логичнее чем “процессы зависли и/или заблокированы”.
Из быстрых work-around’ов в голову приходили либо периодический рестарт haproxy либо отстреливание повисших коннектов.
И тут на глаза мне попался график количества UDP коннектов (UDP_inuse):
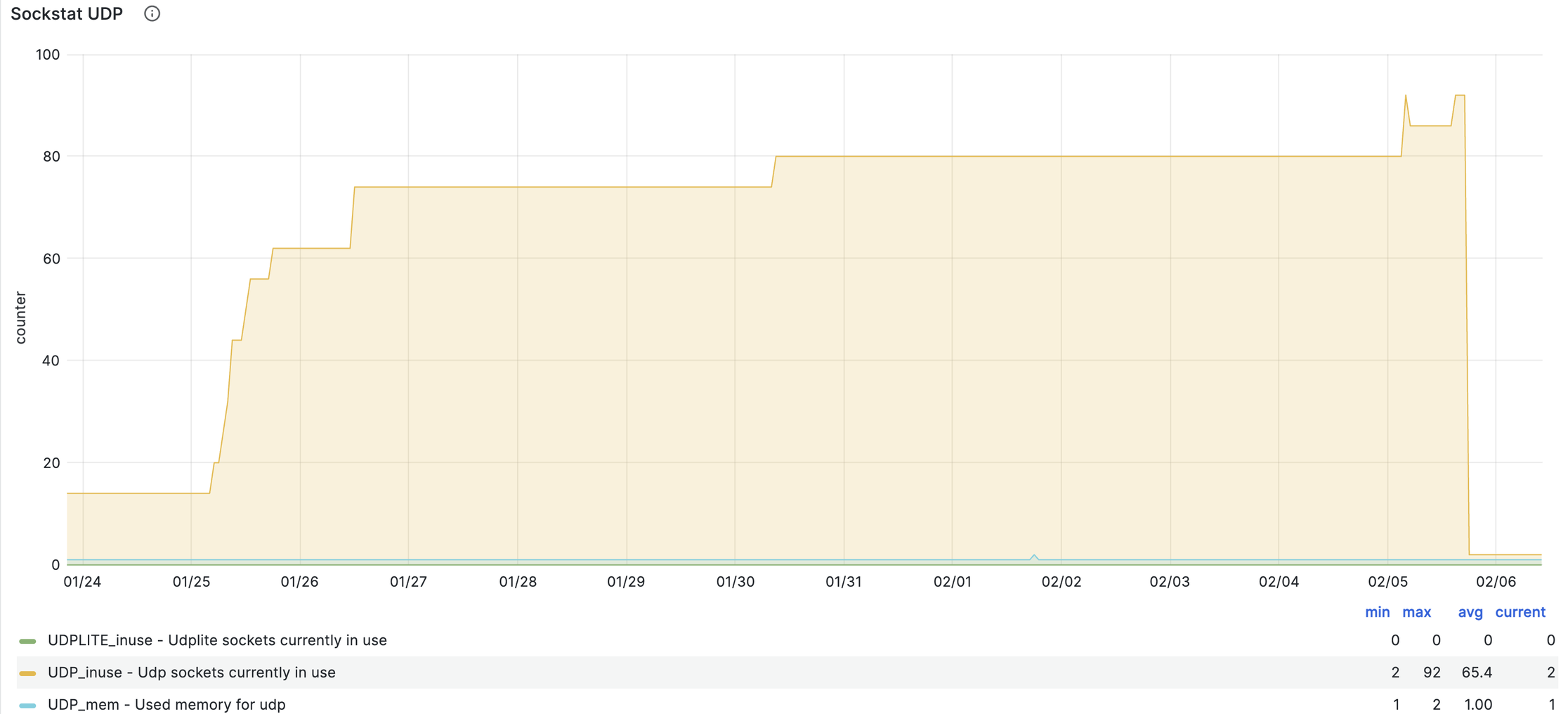
Каждый скачек в количестве соединений хорошо был виден во времени в отличии от аналогичного графика для TCP.
Я сопоставил эти тайминги с данными из atop - в момент роста UDP коннектов добавлялся еще одни процесс haproxy, тогда как существующие не завершались.
И еще раз присмотрелся к systemd логам:
$ journalctl -u haproxy
...
Jan 23 08:58:25 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 23 08:58:25 haproxy[2887591]: [NOTICE] (2887591) : New worker (2931744) forked
Jan 25 04:42:44 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 25 04:42:44 haproxy[2887591]: [NOTICE] (2887591) : New worker (3093691) forked
Jan 25 06:40:45 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 25 06:40:45 haproxy[2887591]: [NOTICE] (2887591) : New worker (3144234) forked
Jan 25 07:06:58 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 25 07:06:58 haproxy[2887591]: [NOTICE] (2887591) : New worker (3157985) forked
Jan 25 07:10:56 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 25 07:10:56 haproxy[2887591]: [NOTICE] (2887591) : New worker (3159942) forked
Jan 25 07:42:50 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 25 07:42:50 haproxy[2887591]: [NOTICE] (2887591) : New worker (3165698) forked
Jan 26 11:11:56 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 26 11:11:56 haproxy[2887591]: [NOTICE] (2887591) : New worker (3387315) forked
Jan 26 11:41:37 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 26 11:41:37 haproxy[2887591]: [NOTICE] (2887591) : New worker (3408004) forked
Jan 30 08:45:37 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Jan 30 08:45:37 haproxy[2887591]: [NOTICE] (2887591) : New worker (3776117) forked
Feb 5 03:58:20 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Feb 5 03:58:20 haproxy[2887591]: [NOTICE] (2887591) : New worker (148797) forked
Feb 5 03:59:15 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Feb 5 03:59:15 haproxy[2887591]: [NOTICE] (2887591) : New worker (149187) forked
Feb 5 04:29:50 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Feb 5 04:29:50 haproxy[2887591]: [NOTICE] (2887591) : New worker (164172) forked
Feb 5 04:47:53 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Feb 5 04:47:53 haproxy[2887591]: [NOTICE] (2887591) : New worker (170279) forked
Feb 5 14:17:46 haproxy[2887591]: Reloaded HAPEE Load Balancer.
Feb 5 14:17:46 haproxy[2887591]: [NOTICE] (2887591) : New worker (218073) forked
...
Пазл стал собираться.
Рестарт haproxy приводил к порождению нового процесса, который в свою очередь активно аллоцировал память под свои нужды (напомню что старые не завершались). Следующий рестарт добавлял еще один процесс и так по кругу, пока критический объем памяти не активировал OOM Killer.
Я наконец добрался до конфига haproxy, что дало мне еще одно подтверждение наличия утечки - балансировщик был настроен с директивой nbthread 6, то есть использовал треды одного воркера. А у нас воркеров были десятки.
Наконец я смог сформулировать проблему и нашел открытый issue HAProxy Reload - Old Processes not finishing.
На данный момент (март 24) баг не вылечен, но есть костыль в виде hard-stop-after директивы, принудительно завершающей процесс старого воркера после таймаута. Эдакий аналог graceful shutdown в kubernetes.
Вот как это выглядит после внедрения 14.03:
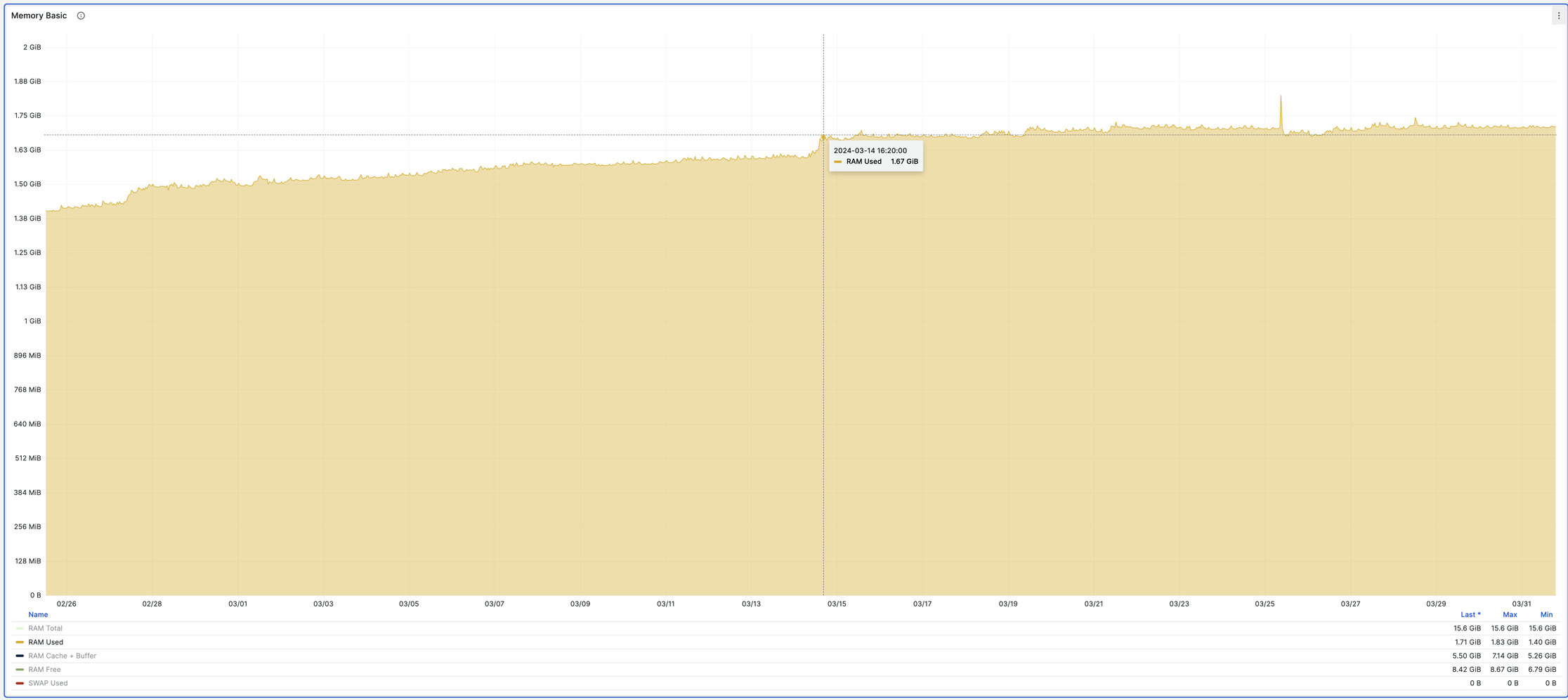
Выводы
При решении проблемы я много раз уходил по ложному пути и путал причину со следствием. Это на мой взгляд не ошибки, скорее обычный рабочий процесс.
К тому же через такие побочные ветви мы и обрастаем недостающей компетенцией, что в будущем будет работать на нас.
Из явных ошибок отмечу:
- недостаточный мониторинг/алертинг/реагирование;
- недостаточная подготовка - приступил к поиску проблем без контекста текущего окружения (зная как балансировщик настроен можно было сразу заподозрить проблему в большом количестве воркер процессов).
- недостаточная “въедливость” в процессе расследования в следствии спешки, усталости - когда наблюдаешь непонятное поведение часто стоит остановиться и разобраться почему это именно так, а не иначе. Но важно держать баланс между любознательностью и фокусом на решение конкретной проблемы.
Такой получился кейс, удачи!