UPD:
- 14.05.24 - добавил блок-схему движения пакета по очередям;
- 01.05.24 - обновил информацию по деятельности
softirqd.
Прежде чем сетевой пакет из сервиса А попадет в сервис Б, ему следует миновать множество систем по середине, где он сделает ни одну остановку.
И, что самое интересное, никто (или ничто) не гарантируем ему успех в конечно счете.
Описать полный путь мне не хватит ни знаний, ни терпения, поэтому сосредоточусь только на конечной части маршрута - пакет прибыл на целевой Хост, где живет сервис Б.
Цели заметки:
- показать через какие остановки, считай очереди, проходит сетевой пакет прежде чем достигнет получателя;
- как мы можем эти очереди мониторить и как на них влиять.
Вводные - общение происходит по TCP протоколу, где конечный Хост работает под Linux. И пусть это будет виртуальная машина.
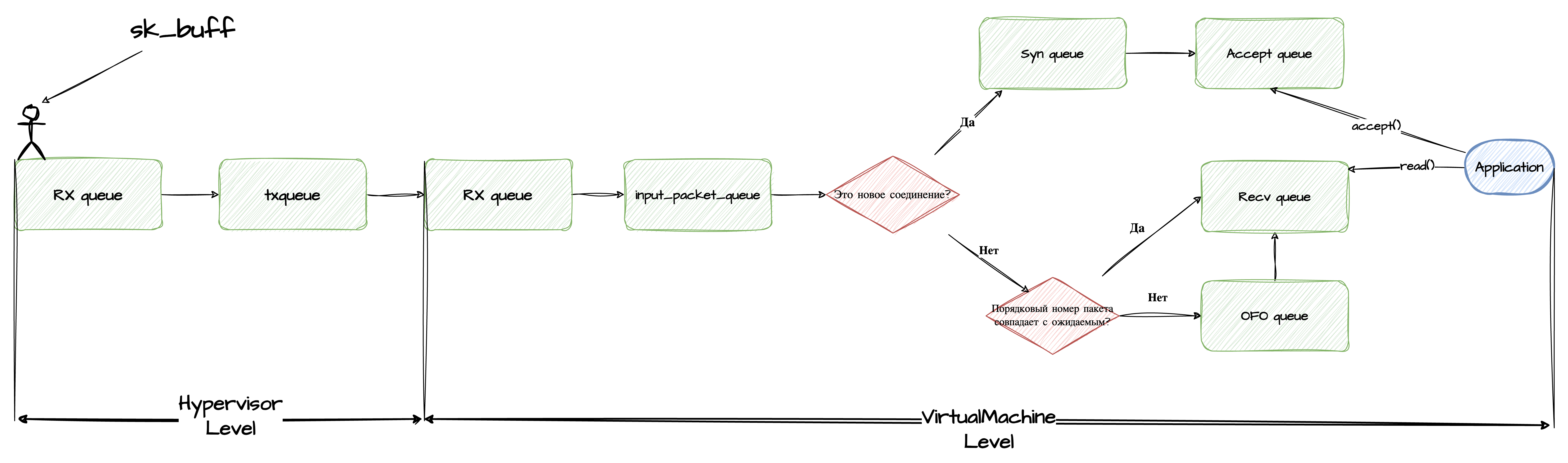
И так, пакет прибыл на Хост…
Первым делом он попадает в сетевую карту (NIC). Через DMA сетевая карта сохраняет его в оперативной памяти в виде структуры sk_buff в кольцевом буфере RX (входящей) очереди.
И это первая остановка.
В зависимости от модели сетевой карты RX очередь, как и их количество, можем конфигурировать через ethtool утилиту:
ethtool -l <interface name> # посмотреть текущее и максимальное количество очередей
ethtool -L <interface name> rx N # изменить текущее количество очередей
ethtool -g <interface name> # посмотреть текущее и максимальную длину очереди
ethtool -G <interface name> rx N # изменить текущий размер очереди
Надо заметить, что определенную очередь будет вычищать определенный CPU, потому в вакууме можно сделать вывод, что чем их очередей больше, тем более равномерно распределяется нагрузка на систему.
Но всегда есть нюансы, о которых полезно помнить и проверять:
- а не хотим ли мы оставлять обработку трафика специально выделенным под это CPU? Трафик на одних ядрах, сервисы живут на других…меньше прерываний, повышение локальности кешей…
- а что если у нас половина ядер “нечестных” (включен hyperthreading), будут ли 32 очереди на 16 настоящих ядрах (32 виртуальных) работать быстрее нежели к примеру 8 очередей с теми же вводными?
Вообщем есть о чем подумать и что потестировать.
Наблюдать за переполнением возможно через файлы:
/sys/class/net/<interface name>/statistics/rx_dropped;/proc/net/dev.
node_exporter любезно собирает эти данные через метрику node_network_receive_drop_total , что доступна на стандартном дашборде Node Exporter Full.
💡 Еще одна пометка - я сознательно пропускаю из рассмотрения такую штуку как Qdisc (queuing discipline), надеюсь вернуться к ней в будущем.
После того как систему через прерывания (hard/soft) известили о наличии пакета, за работу принимается рутина ядра softirqd - разгребая RX очередь.
Подобно любой другой рутине ее выполнение на CPU определяется linux scheduler и как следствие конечно по времени.
При большом объеме сетевого трафика в рамках конкретного планирования на CPU softirqd может не успеть опустошить всю RX очередь, что чревато увеличению latency. В таких случаях растет счетчик так называемых сквизов (squeezes).
К счастью есть возможность влиять на поведение рутины через настройку бюджетов. Работа softirqd в рамках одного планирования завершится либо когда истечет net.core.netdev_budget_usecs либо число обработанных пакетов станет равным net.core.netdev_budget.
Для наблюдения за работой softirqd возможно через файл /proc/net/softnet_stat либо с помощью метрик:
node_softnet_processed_totalnode_softnet_times_squeezed_total
Как было указанно в начале заметки сетевой пакет предназначется виртуальной машине, а значит в итоге после обработки на уровне гипервизора он попадает в очередь tap-интерфейса txqueue.
tap-интерфейс - это тот, который одной стороной смотрит на хостовую машину, а другой в виртуальную.
Подробнее про реализацию читай в блоге cloudflare.
Узнать длину очереди (qlen) можно командой:
ip a | grep tap69035i0
43: tap30035i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr30035i0 state UNKNOWN group default qlen 1000
где tap69035i0 имя интерфейса ВМ с точки зрения гипервизора, в proxmox задается параметром ifname.
В нашем случае qlen равна 1000.
Интересно, что очередь называется txqueue, то есть исходящая, так как с точки зрения гипервизора пакет покидает Хост, направляясь дальше к Виртуальной машине. Это может вводить в заблуждение.
Следить за переполнением на хостовой машине помогает файлики:
/sys/class/net/<interface name>/statistics/tx_dropped;/proc/net/dev.
node_exporter отслеживает эти события через node_network_transmit_drop_total.
Изменяется стандартное значение через
ip link set dev* <interface name> txqueuelen N
Стоит отметить, что переполнение txqueue tap/tun интерфейса часто упускается из рассмотрения, так как метрика принадлежит гипервизору, что полностью скрыто от уровня виртуальной машины. Постараемся решить эту проблему далее.
Наконец пакет готов подняться на уровень виртуальной машины. Рассмотрим его в следующей заметке.
Удачи!