Наблюдаемость и простота отладки одни из важнейших свойств системы, которые следует учитывать уже на этапе выбора технологий. В противном случае может быть больно и дорого.
Следующий этап - разобраться как технология устроена и желательно сделать это еще до развертывания в боевых окружениях. Но бывает конечно по всякому.
Сегодня рассмотрим сеть в Kubernetes и выявим несоответствия в учете трафика, которые могут вводить в заблуждение.
Дано:
- Kubernetes кластер;
- MetalLB L2 как
loadBalancer; - Nginx Ingress Controller;
- Calico на ebpf.
Мы обнаружили рассинхронизацию в объеме сетевого трафика на MetalLB по сравнению с Ingress Controller: на Ingress Controller трафика было значительно больше.
MetalLB:
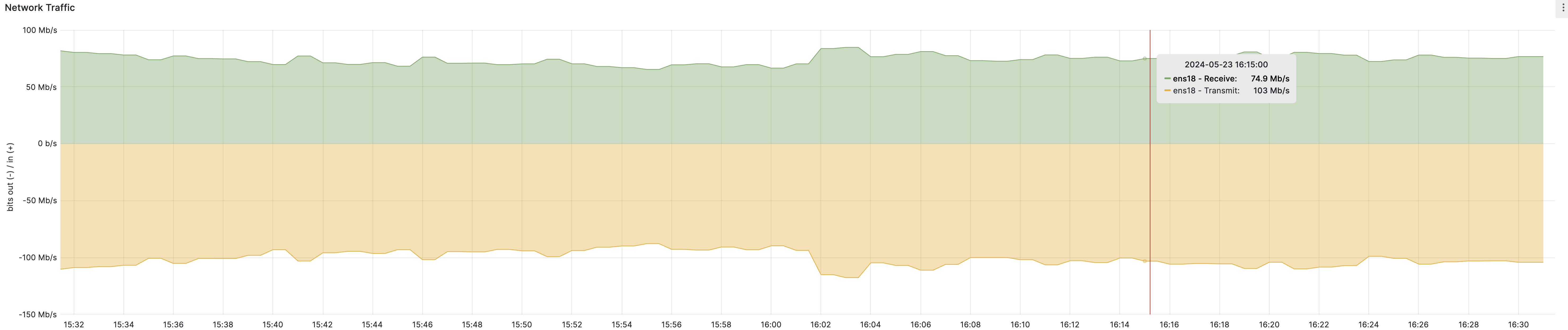
Ingress Controller:

Как мне казалось это работает
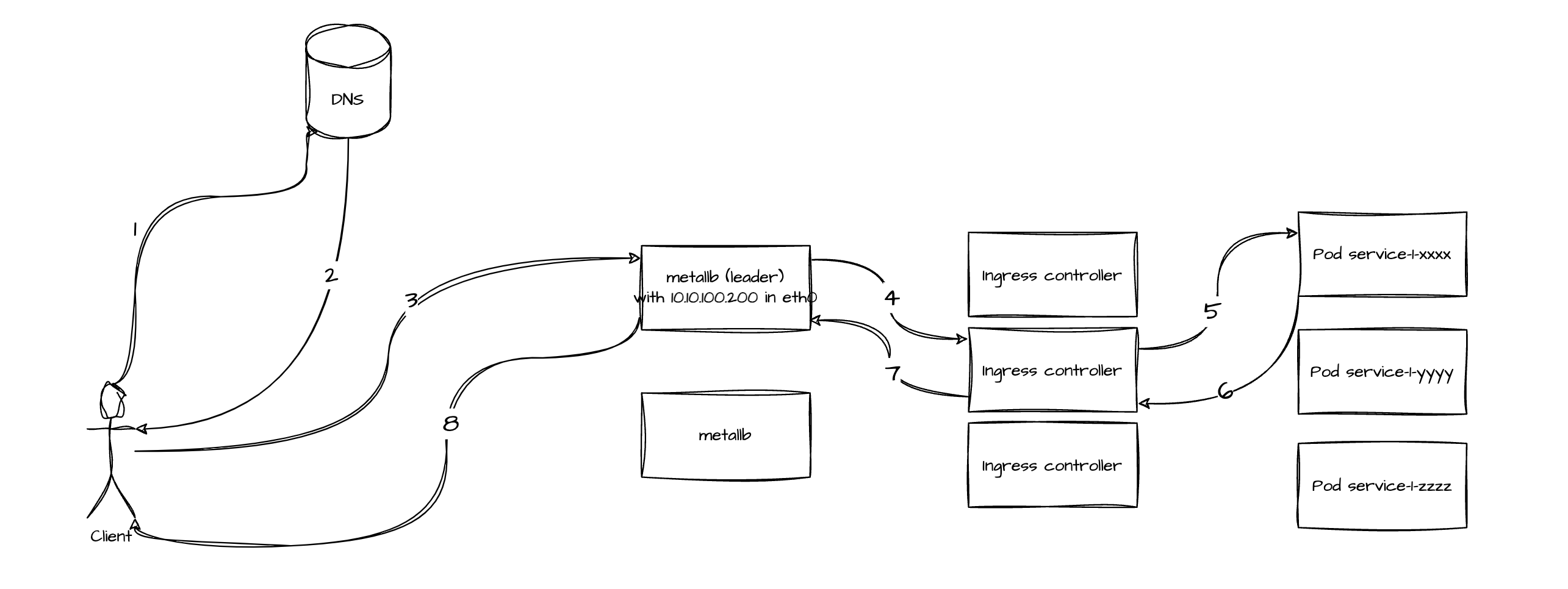
- клиент резолвит IP (далее
VIP)loadBalancerи переходит по нему; - попадает на один из экземпляров MetalLB (лидер);
- за
VIPстоит набор Ingress Controller машин и запрос падает на один из них; - Ingress Controller проксирует трафик через абстрацию
svcв конкретный Под; - ответ по цепочке возвращается обратно.
MetalLB является точкой входа в кластер, и ожидается, что объем трафика на нем будет аналогичен объему на Ingress Controllers. Однако фактические данные говорят об обратном.
А точно ли MetalLB единая точка входа?
Согласно документация так и есть:
In layer 2 mode, all traffic for a service IP goes to one node. From there, kube-proxy spreads the traffic to all the service’s pods.
Перепроверяем:
# dig service-1.k8s.local +short
10.10.100.200
# arping 10.10.100.200
ARPING 10.10.100.200
60 bytes from 1a:33:e2:2c:43:38 (10.10.100.200): index=0 time=411.542 usec
60 bytes from 1a:33:e2:2c:43:38 (10.10.100.200): index=1 time=599.265 usec
60 bytes from 1a:33:e2:2c:43:38 (10.10.100.200): index=2 time=532.545 usec
### на MetalLB машине:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 1a:33:e2:2c:43:38 brd ff:ff:ff:ff:ff:ff
altname enp0s18
...
MAC-адрес в выводе arping совпадает с MAC-адресом интерфейса MetalLB. Всё сходится.
А что за пакеты проходят через MetalLB?
Заглянем в дамп трафика:
No Time Source Destination Info
1 15:13:56.472036 10.10.8.25 10.10.100.200 34092 → 80 [ACK] Seq=1 Ack=1 Win=502 Len=0 TSval=3251525178 TSecr=2555063318
2 15:13:56.472037 10.10.5.50 10.10.100.200 45950 → 80[Packet size limited during capture]
3 15:13:56.472043 10.10.20.238 10.10.100.200 54280 → 80[Packet size limited during capture]
4 15:13:56.472046 10.10.13.114 10.10.100.200 47668 → 80[Packet size limited during capture]
5 15:13:56.472052 10.10.20.165 10.10.100.200 53370 → 80[Packet size limited during capture]
6 15:13:56.472062 10.10.8.25 10.10.100.200 34092 → 80[Packet size limited during capture]
7 15:13:56.472075 10.10.18.168 10.10.100.200 58238 → 80 [ACK] Seq=1 Ack=1 Win=494 Len=0 TSval=1930657863 TSecr=3343416628
8 15:13:56.472082 10.10.18.168 10.10.100.200 58238 → 80[Packet size limited during capture]
...
… и мы видим только входящий в кластер трафик, но не исходящий.
Магия?
Как это работает на самом деле
MetalLB является kubernetes native сущностью, а значит сеть для нее строит Calico:
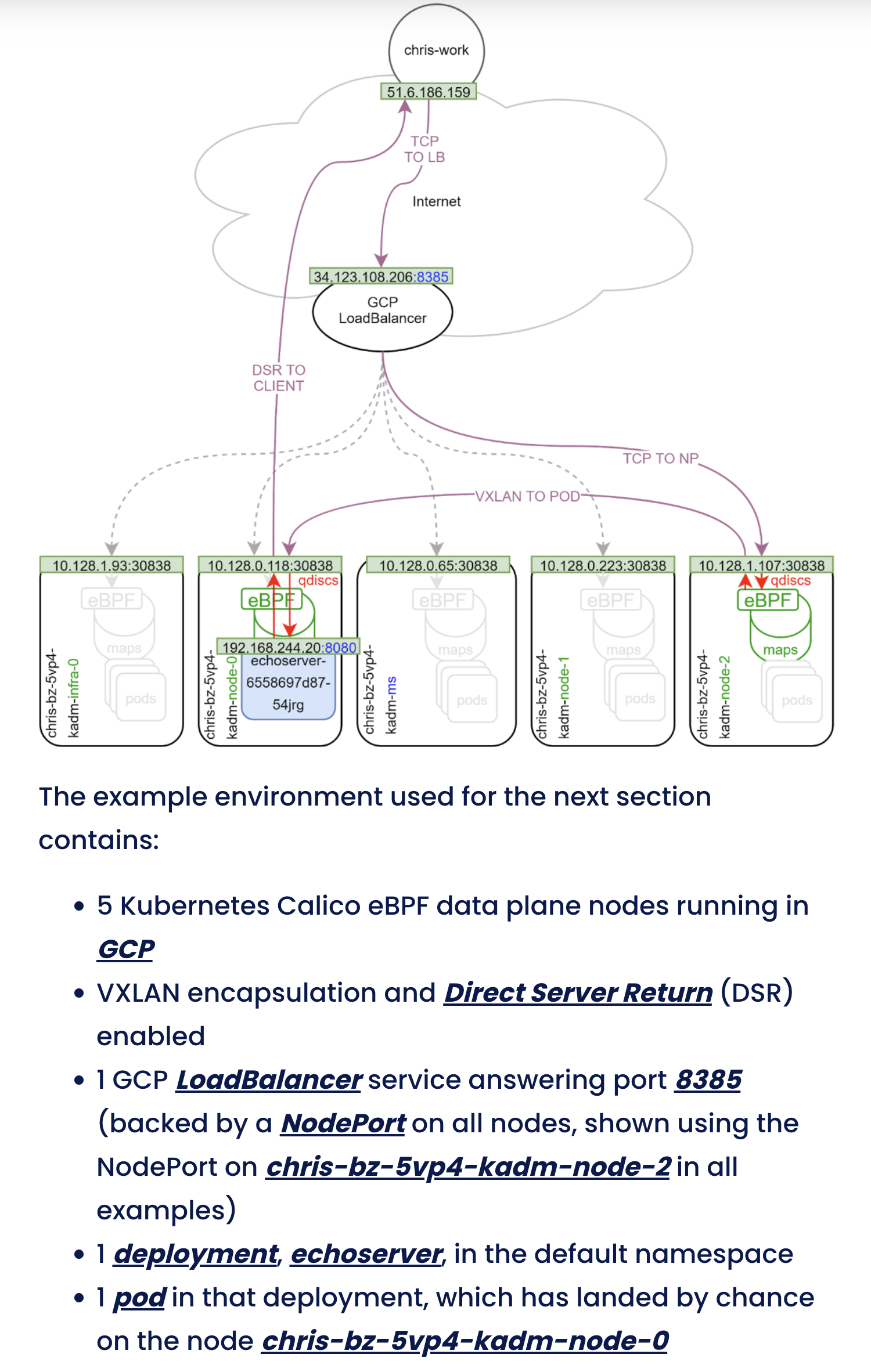
источник https://www.tigera.io/blog/calico-ebpf-data-plane-deep-dive/
Таким образом путь трафика вплоть до целевого сервиса совпадает c изначальным предположением. Отличия начинаются после.
Calico в ebpf режиме использует Direct Server Return или DSR, что позволяет направлять ответный трафик к клиенту минуя балансировщик, MetalLB в нашем случае.
Чтобы такое провернуть входящий пакет перехватывают на уровне подсистемы tс (traffic control), где его метаданные складывают в ebpf структуру (map).
То же относится и к ответному пакету: перехватят в tc, сопоставят с метаданными его TCP потока и направят мимо балансировщика напрямую клиенту:
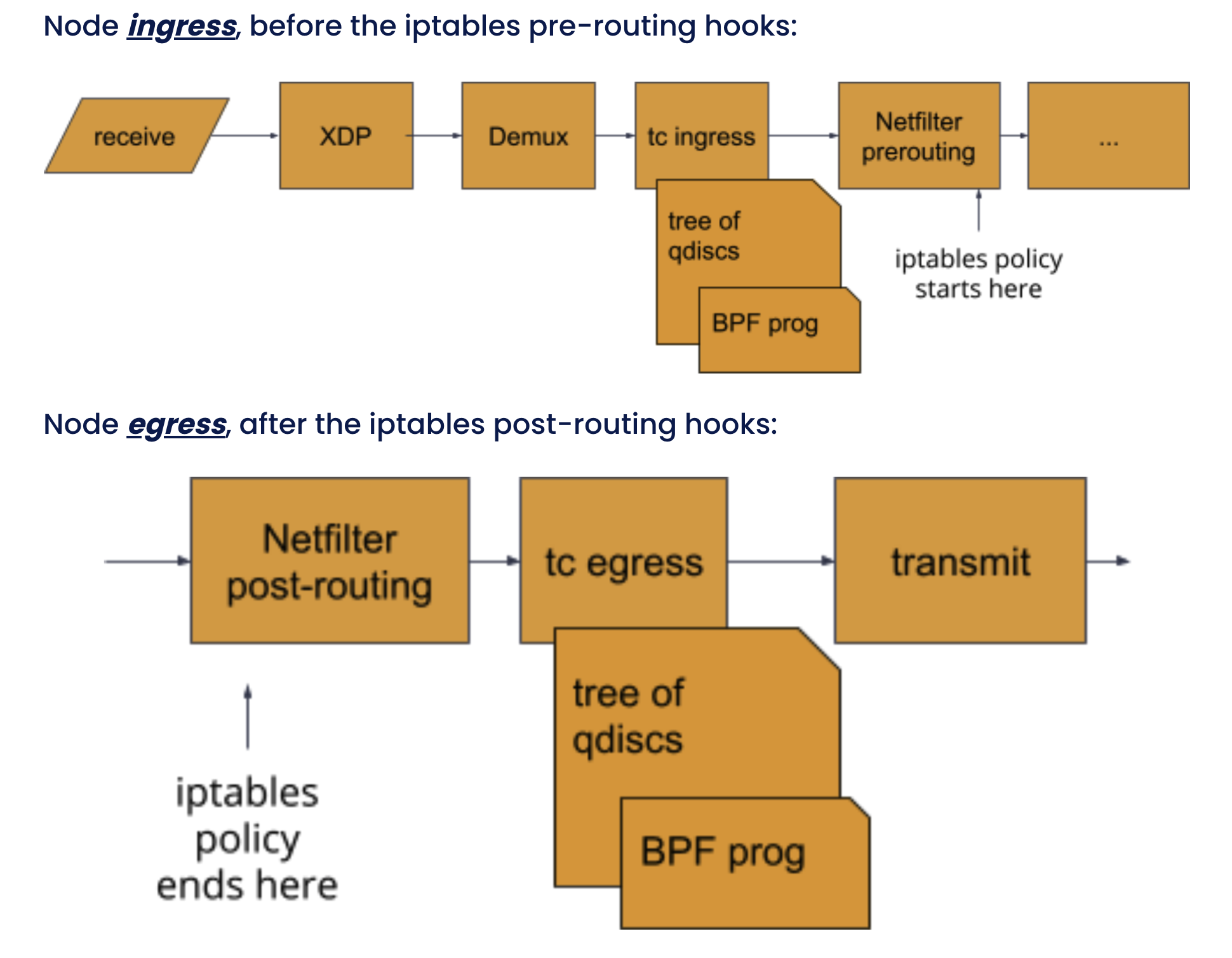
Поэтому и наблюдаем различия на несколько порядков в объемах трафика между MetalLB и Ingress Controller.
Удачи!
Еще я есть в telegram - https://t.me/troubleperf. Присоединяйся!