Проблематика
Чтобы оценить производительность ввода/вывода обычно принято обращаться к метрикам дисковой подсистемы, благо они богато представлены “стандартными” инструментами linux - sar, iostat, atop, etc.
Проблема данного подхода, в упрощении общей картины, он игнорирует такой важный компонент в работе I/O подсистемы как файловая система.
Например:
- приложение может использовать асинхронную модель записи и flush на диск происходит порциями и когда-то потом;
- приложение хочет прочитать 1 байт данных, но считать с диска возможно только блоком в 4096 байт;
- используется read-ahead при последовательном чтении;
- чтение происходит из кеша файловой системы - запросов на чтение много, а диск почти не загружен;
и так далее.
Все это может вводить в заблуждение и в моменте неправильно интерпретироваться.
(инструментацию ввода/вывода приложения оставлю за скобками - дорого, сложно масштабировать и редко встречается)
Выход есть
В проекте iovisor/bcc есть множество инструментов для исследования работы linux.
В частности утилиты xfsdist, ext4dist, zfsdist, btrfsdist, nfsdist помогают строить гистограммы задержек операций уровня файловой системы - read() , write(), sync(), open():
# https://github.com/iovisor/bcc/blob/master/tools/xfsdist_example.txt
$ ./xfsdist
Tracing XFS operation latency... Hit Ctrl-C to end.
^C
|
operation = b'read'
usecs : count distribution
0 -> 1 : 421818 |******************************|
2 -> 3 : 270492 |****************
4 -> 7 : 4634 |
8 -> 15 : 2723 |
16 -> 31 : 1089 |
32 -> 63 : 1558 |
64 -> 127 : 1024 |
128 -> 255 : 921 |
256 -> 511 : 146 |
512 -> 1023 : 1 |
1024 -> 2047 : 2 |
2048 -> 4095 : 3 |
4096 -> 8191 : 34 |
operation = b'write'
usecs : count distribution
0 -> 1 : 324 |
2 -> 3 : 30594 |******************************|
4 -> 7 : 7869 |*****
8 -> 15 : 3267 |***
16 -> 31 : 1373 |*
32 -> 63 : 401 |
64 -> 127 : 56 |
128 -> 255 : 24 |
256 -> 511 : 3 |
512 -> 1023 : 1 |
...
Для получения задержек на уровне дисков можно задействовать утилиту biolatency:
# <https://github.com/iovisor/bcc/blob/master/tools/biolatency_example.txt>
$ ./biolatency
flags = Read
usecs : count distribution
0 -> 1 : 0 |
2 -> 3 : 0 |
4 -> 7 : 0 |
8 -> 15 : 0 |
16 -> 31 : 265 |***********
32 -> 63 : 707 |*****************************|
64 -> 127 : 95 |****
128 -> 255 : 45 |*
flags = Write
usecs : count distribution
0 -> 1 : 0 |
2 -> 3 : 0 |
4 -> 7 : 0 |
8 -> 15 : 0 |
16 -> 31 : 0 |
32 -> 63 : 37 |*
64 -> 127 : 123 |******
128 -> 255 : 741 |*****************************|
256 -> 511 : 636 |*************************
512 -> 1023 : 93 |*****
1024 -> 2047 : 11 |
...
Сопоставив оба сниппета можно сделать выводы:
- чтение (всегда синхронная операция) в основном удовлетворяются из кеша файловой системы - до диска доходит лишь малая доля запросов и с точки зрения приложения чтение завершается за миллисекунды;
- операции записи в массе асинхронные и скопом скидываются на диск позже (write-back) - опять же различные объемы и длительность операций.
Подобные метрики дают возможность:
- пролить свет на работу файловых систем;
- отделить задержки уровня ФС от дисков, что на круг позволит делать более точные выводы о их работы и упрощать поиск корневых причин в случае проблем.
Немного картинок в grafana
Для лучшей визуализации и анализа исторических данных я адаптировал xfsdist (PR) и ext4dist (PR) утилиты под использование в ebpf_exporter, теперь они доступны в grafana:
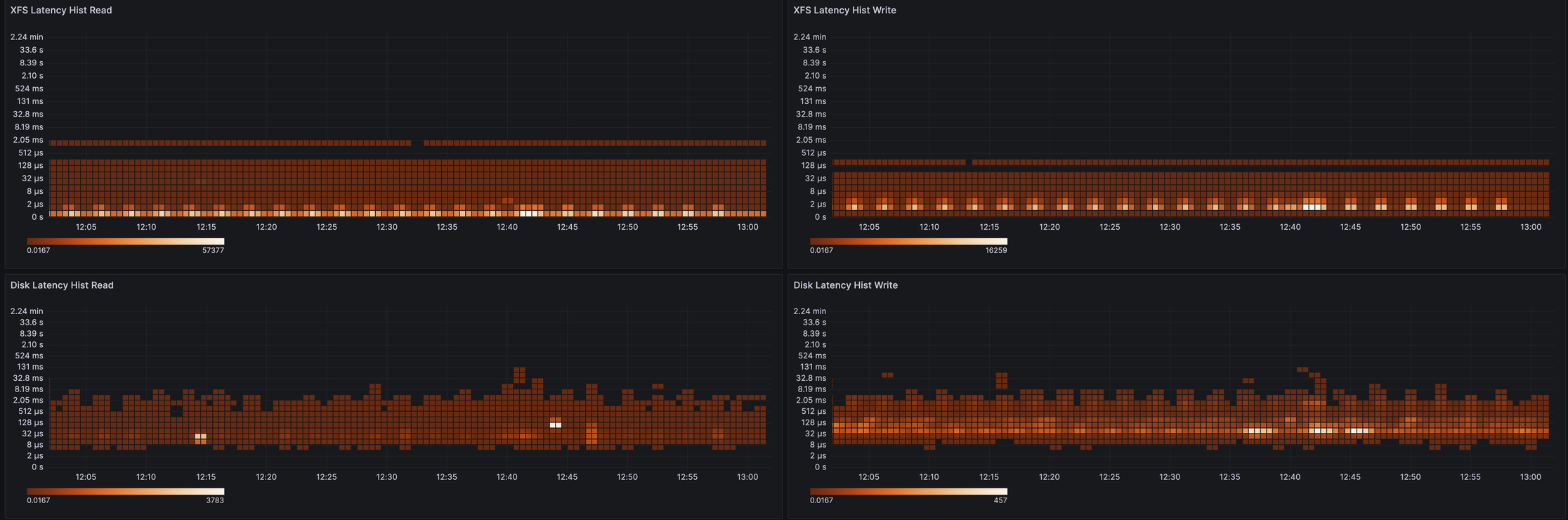
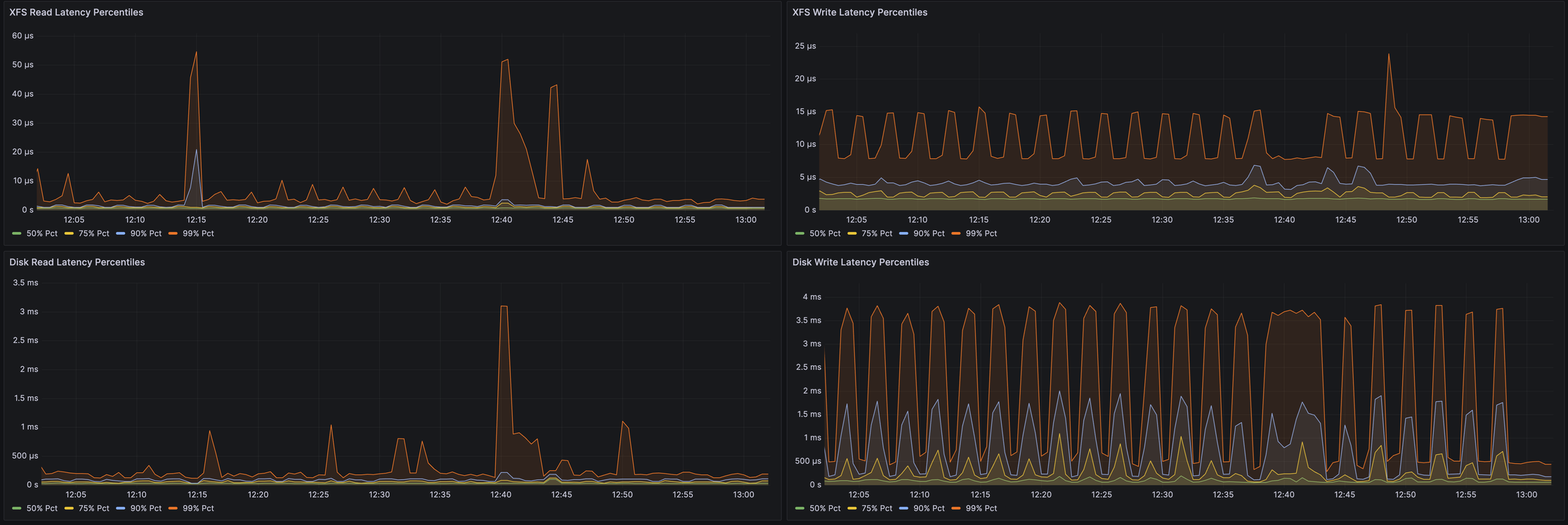
А так это выглядит на процентилях:
Примеры PromQL-запросов:
- гистограмма:
sum(rate(ebpf_exporter_xfs_latency_seconds_bucket{operation="read"}[$__rate_interval])) by (le) - процентили:
histogram_quantile(0.90, sum(rate(ebpf_exporter_bio_latency_seconds_bucket{operation="read"}[$__rate_interval])) by (le, instance))
Подобные метрики должны быть по душе владельцам нагруженных IO сервисов, которые хотят быть чуть глубже осведомлены о поведении своих систем.
Удачи!